The Architecture of Claude Code
AsyncGenerator pipelines, the ReAct core loop, the dependency-injected permission system, write-ahead transcript persistence, and the six patterns composing the whole system.

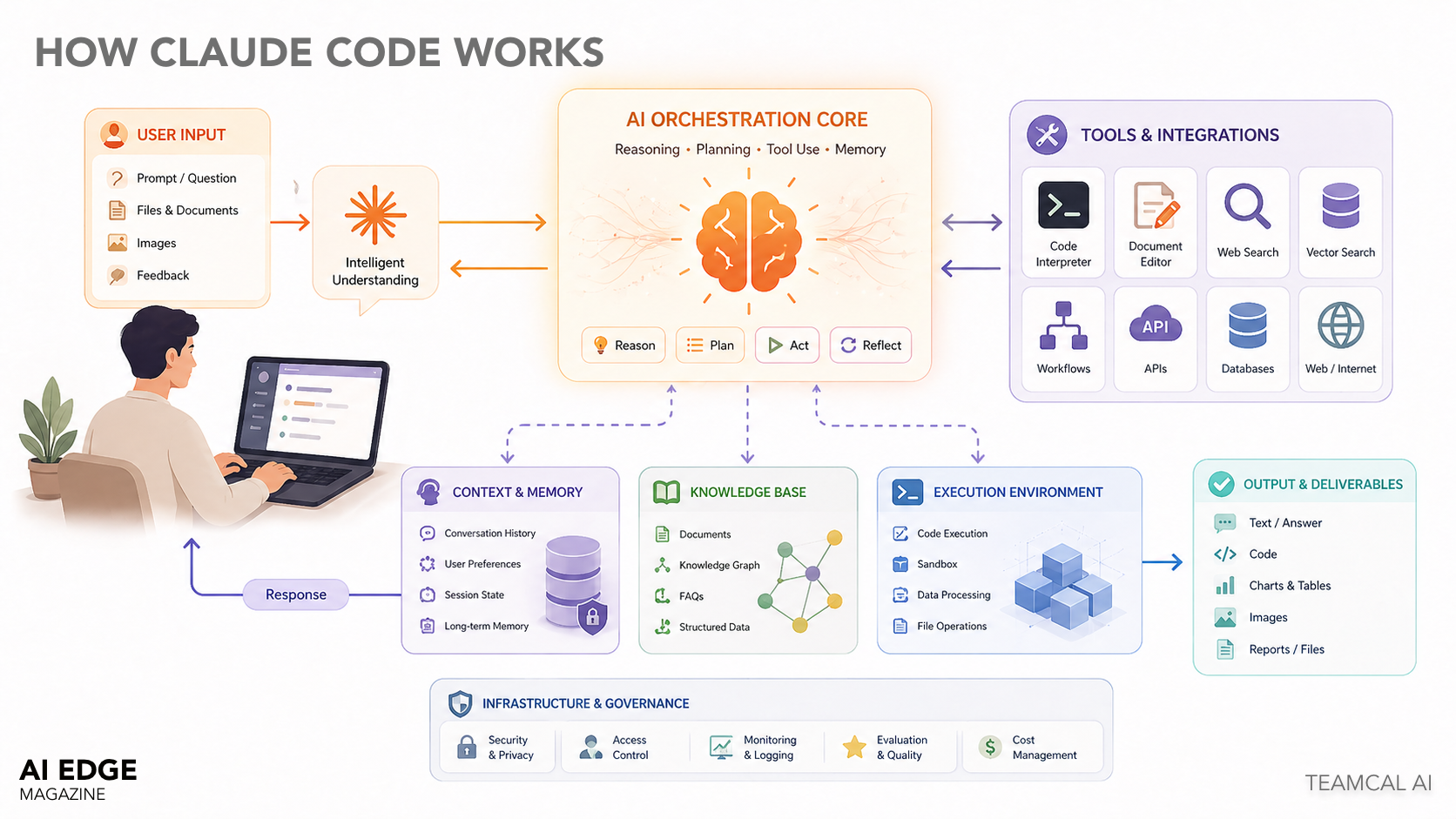
Claude Code's architecture is, on first read, a series of unremarkable choices. That is the interesting part. Each individual pattern — the ReAct loop, the AsyncGenerator pipeline, the dependency-injected permission system, the write-ahead transcript — is well-understood in isolation. The system feels different because of how they compose, and because of four specific architectural shifts that I think are worth stealing for your own agentic systems.
This article walks through the architecture layer by layer, calling out the design decisions that matter and the ones that are merely conventional. I am writing it from the perspective of someone evaluating the system for adoption, or building something similar. If you want the marketing version, go read the executive article.
Runtime & Build
Bun is the runtime. The build system uses feature('FLAG') from bun:bundle to enable build-time dead code elimination. Conditional require() calls are tree-shaken at bundle time, not guarded at runtime. TypeScript end-to-end with Zod schemas for runtime validation at I/O boundaries.
The notable thing here is the bundler is being used as a security primitive, not just a packaging tool. Code paths that should not exist in a given build literally do not exist in the artifact, rather than being feature-flagged at runtime. That is a different threat model than most TypeScript projects assume. It also means a misconfigured runtime cannot accidentally enable a code path that was supposed to be off — the path is gone.
Practical implication: if you are building your own agentic system and you want to mirror this property, you cannot do it with conditional logic. You have to push it into the build pipeline.
Entry Points
// Entry hierarchy
src/main.tsx → Commander.js CLI setup, bootstraps everything
src/entrypoints/ → Variant entrypoints (CLI, SDK, headless)
src/query.ts → Raw streaming loop against the Anthropic API
src/QueryEngine.ts → Stateful conversation wrapper around query.ts
// ask() is a one-shot convenience wrapper around QueryEngine
// QueryEngine is the class for multi-turn sessionsTwo distinct query primitives matter here: query.ts is the raw streaming loop, QueryEngine.ts is the stateful wrapper. If you are building on top of Claude Code, you almost always want QueryEngine. If you are reading the code to understand it, start at query.ts. The mental separation between them is one of the cleaner aspects of the codebase.
QueryEngine — Where the Agent Actually Lives
submitMessage() is an AsyncGenerator<SDKMessage>. The call chain:
submitMessage(prompt)
→ processUserInput() // slash command handling, normalization
→ fetchSystemPromptParts() // build system prompt from tools/context/memory
→ query() // streams messages from Anthropic API
→ for await (message of query(...))
→ switch(message.type) // route each message type
→ recordTranscript() // persist to disk (WAL pattern)
→ yield SDKMessage // stream to caller
→ yield result // terminal: cost, usage, stop_reasonThe use of AsyncGenerator as the universal interface is one of the more interesting choices in the codebase. Every layer — user input, model output, tool calls, sub-agents — is exposed as an async iterable, which means composition is trivial. A sub-agent is just another async iterable that you can plug into the same for await loop. Streaming back-pressure is handled by the language, not the framework.
for await loop. Composition is trivial because the shape is uniform.Message Types — Discriminated Union
Every message yielded by query() is one of these types, dispatched by a switch on message.type:
| Type | Meaning |
|---|---|
assistant | Claude text or tool_use content block |
user | Tool results or user input fed back |
progress | In-flight tool execution update |
stream_event | Raw Anthropic SSE events (opt-in via includePartialMessages) |
attachment | Structured output, max_turns signal, queued commands |
system/compact_boundary | Context window compaction checkpoint |
system/api_error | Retryable API error with backoff metadata |
result | Terminal — success, error_max_turns, error_max_budget, error_during_execution |
This pattern is common enough in TypeScript codebases that it does not need defending. The interesting part is the uniformity — system events, errors, progress updates, and final results all flow through the same channel. Errors are not exceptions; they are messages. That makes them composable in the same way successful results are composable, which is the entire point of the AsyncGenerator architecture.
Permission as a Streaming Concern
canUseTool is injected as a dependency. submitMessage wraps it to track denials — a wrapper pattern that adds cross-cutting concerns without modifying the underlying interface:
// QueryEngine.ts:244 — denial tracking wrapper
const wrappedCanUseTool: CanUseToolFn = async (...) => {
const result = await canUseTool(...)
if (result.behavior !== 'allow') {
this.permissionDenials.push({ tool_name, tool_use_id, tool_input })
}
return result
}The architectural decision worth noting: permission is not a static decorator on tool definitions, it is a runtime decision evaluated against streaming context. This is what allows the three-tier system (org-level, project-level, session-level) to be configured independently and still resolved correctly per-call.
If you are building your own agentic system, this is one of the patterns I would steal. The temptation is to attach permission metadata to tool definitions at registration time. That approach falls apart the moment you need to express "this tool is allowed for user A but not user B in project context C." Streaming-time permission resolution makes that trivial.
Functional Updates, External Storage
AppState is passed via getAppState / setAppState callbacks — an immutable functional update pattern (Redux-style reducers, no store library). The engine never holds AppState directly:
setAppState(prev => ({
...prev,
toolPermissionContext: {
...prev.toolPermissionContext,
alwaysAllowRules: { command: allowedTools }
}
}))
// Key state slices: toolPermissionContext, fileHistory, attribution, fastModeThe reason this matters: by keeping state external to the engine, the engine itself remains a pure stream transformer. You can run two QueryEngine instances against the same AppState in parallel without thread-safety concerns, because the engine never mutates state directly — it only emits state-update functions for the caller to apply.
System Prompt Assembly
fetchSystemPromptParts() builds three composable parts:
defaultSystemPrompt → tool definitions, Claude's identity, capabilities
userContext → { cwd, os, date, memory, coordinator context... }
systemContext → internal context injected as <system> blocks
// Memory injected only when customSystemPrompt +
// CLAUDE_COWORK_MEMORY_PATH_OVERRIDE are both setThe separation between what Claude is (defaultSystemPrompt), where Claude is (userContext), and what the operator wants Claude to know (systemContext) is a clean conceptual split that pays off when you start composing with sub-agents — each sub-agent gets a different blend.
The Transcript Is a Write-Ahead Log, Not a Chat History
This is one of the more carefully designed parts of the codebase.
// Assistant messages → fire-and-forget (non-blocking between content blocks)
void recordTranscript(messages)
// User / tool_result messages → await (must be durable before next API call)
await recordTranscript(messages)
// User message written BEFORE entering query loop (WAL pattern)
// If process killed between send and response → session still resumableThe mental model here is borrowed from database systems: a write-ahead log. You commit the user's intent to disk before attempting the action. If the system crashes mid-action, the intent is still recorded, and the session can be resumed cleanly.
If you have ever debugged an LLM-powered application that lost user input because the API call failed mid-stream, you understand why this matters. WAL semantics fix it cleanly.
Context Compaction
Two strategies for keeping the context window from blowing out:
compact_boundary is a summarization checkpoint. Pre-boundary messages are spliced from mutableMessages for garbage collection. The boundary itself stays in place as a resume anchor.
HISTORY_SNIP (feature-gated) is a finer-grained snip compaction strategy. It is injected via a snipReplay callback, which means excluded strings stay out of QueryEngine.ts entirely — a clean separation between what the engine knows about and what the operator chooses to expose.
Budget Guards
Two inline checks inside the for await loop yield terminal result messages:
- USD budget — if
getTotalCost() >= maxBudgetUsd, yieldserror_max_budget_usd - Max turns — signaled via
attachment.type === 'max_turns_reached'fromquery.ts - Structured output retries — counts
SYNTHETIC_OUTPUT_TOOL_NAMEtool calls; if>= MAX_STRUCTURED_OUTPUT_RETRIES, yields error
Notable design choice: budget guards yield messages rather than throw exceptions. This keeps the budget-exceeded path indistinguishable in shape from the success path. Callers iterate the same for await loop and switch on message.type. Errors compose. Exceptions do not.
MCP and Built-In Tools, Indistinguishable
Tools implement a common interface from src/Tool.ts. At query time, the list is serialized into Anthropic's tool schema. When Claude returns a tool_use block, query.ts dispatches to the matching tool, runs permission checks, executes, and feeds tool_result back as the next user message. MCP tools are dynamically discovered and registered identically to built-in tools.
That last sentence is the design point. MCP is not a special case in the codebase. The tool interface treats internal tools and external MCP tools identically. Which means the surface area for adding capabilities is the size of the MCP ecosystem, not just what Anthropic ships.
For anyone integrating Claude Code, this is the lever that matters most. Custom tools deployed via MCP get full access to the same permission system, the same streaming pipeline, the same transcript log. There is no second-class API for extensions.
The Six Patterns, and the Four Worth Stealing
Six patterns are doing most of the work in this architecture:
| Pattern | Where it lives | What it buys you |
|---|---|---|
| ReAct loop | query.ts | The agentic core — model decides, tool runs, result feeds back |
| Tool interface | src/Tool.ts | Open/closed extensibility — new tools without engine changes |
| AsyncGenerator pipeline | Throughout | Universal streaming glue — every layer is an async iterable |
| Dependency injection | QueryEngine.ts constructor | The seam pattern — testability, configurability, composition |
| Discriminated union dispatch | Message handling | Type-safe message bus — events, errors, progress all on one channel |
| Build-time feature flags | Bun bundler | Bundler as macro system — eliminates code paths, not just behavior |
None of these patterns is novel in isolation. The composition is what makes the system feel different from typical agent frameworks. The model is the orchestrator, not a hand-coded state machine. The bundler is a security primitive, not just a packaging tool. The transcript is a write-ahead log, not a chat history. The tool layer treats internal and external capabilities identically.
If you are building your own agentic system, those four shifts — model-as-orchestrator, bundler-as-primitive, transcript-as-WAL, tool-as-interface — are the ones worth stealing.
What This Architecture Means for the Field
The reason this architecture matters beyond Claude Code itself: it is a working reference implementation of how to build agentic AI systems that are both extensible and safe. Most attempts at agentic systems fail one of those two tests. They are extensible but unsafe (the demo crowd), or safe but inflexible (the enterprise crowd). Claude Code's architecture shows there is a way to get both, and the way is the patterns above.
At TEAMCAL AI, the architecture behind Zara, our AI scheduling agent, leans on similar principles. Streaming-time permission resolution. Tool layer that treats integrations uniformly. Persistent context that survives session boundaries. The shape of a well-built agentic system in 2026 is converging, and Claude Code is one of the cleaner published examples.
If you are building in this space, read the source. The patterns are clearer in code than they are in any architecture diagram, including the ones in this article.